BigData 激情不再,得回到資料分析本質(例:資料視覺化、統計方法、實務應用)
2015/11/9
R 套件異常時如何重新安裝
最近碰到一個奇怪的問題,使用 ggfortify 套件,想要將迴歸的圖形利用 autoplot 輸出發生了問題,顯示 “no layers in plot”
程式碼:
library( ggfortify)
autoplot (lm(Sepal.Length ~ Sepal.Width , data = iris))
異常訊息:
“no layers in plot”
但如果是要繪裂 pca 等統計圖形則正常 …
分別用以下2種方式重新安裝套件都無法解決
(1)
install.packages('ggfortify')
會顯示警告訊息:
Warning in install.packages :
package ‘ggfortify’ is not available (for R version 3.2.2)
(2)
library(devtools)
install_github('sinhrks/ggfortify')
能安裝,但依舊無解
上網查到的解法如下:
install.packages('ggfortify', dependencies=TRUE, repos='http://cran.rstudio.com/')
另外也利用 Rstudio 檢查了久未更新的其他套件,將其一併更新…
終於可以正常執行 autoplot 指令
參考網址:
http://stackoverflow.com/questions/25721884/how-should-i-deal-with-package-xxx-is-not-available-for-r-version-x-y-z-wa
2015/10/30
Windows系統讀取包含日文、韓文的UTF8 文件 [R]
眾所皆知,w indows系統在處理編碼上是非常弱勢的;
相對於 linux 與 mac 在讀寫各式不同編碼的純文件時,只需要指定好 encoding 的內容就可以正常讀取;目前經過我交叉測試,在windows中如果UTF8文件中包含了日文、韓文的UTF8文件還是無法正確讀取…
將問題與解法整理成如下2張圖:
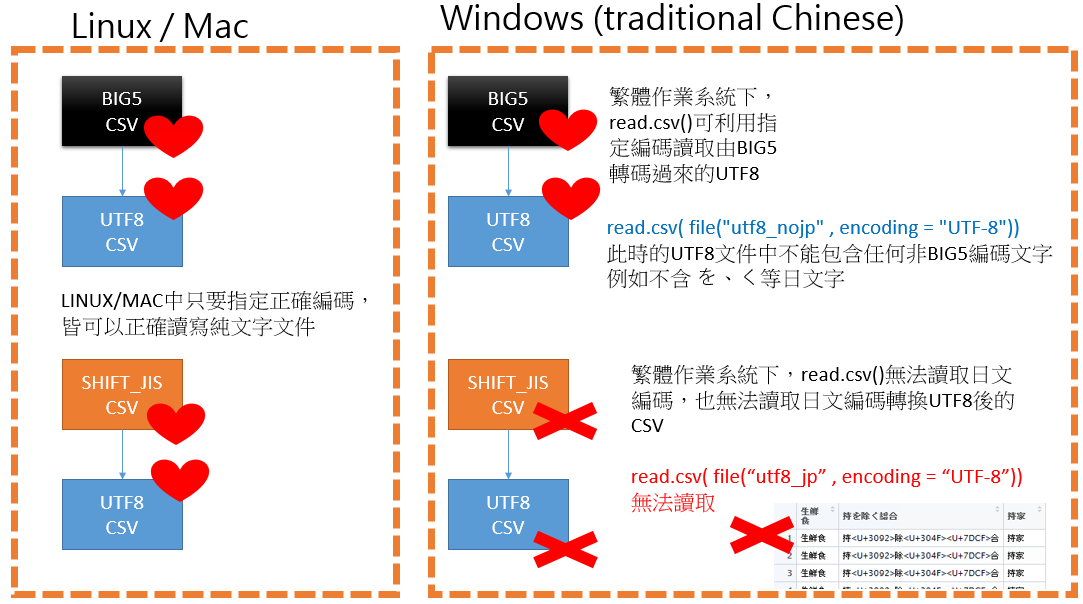

可依情境加以使用不同解決方案,這2種方式都可以正確讀取含有日文、韓文等文字的UTF8文件…若使用原始系統搭載的 read.csv() 則執行指令時會報錯!!
備註:
(1)readxl套件,請參考:
http://www.r-bloggers.com/get-data-out-of-excel-and-into-r-with-readxl/
(2)readr套件,請參考:
http://www.r-bloggers.com/readr-0-2-0/
readr還含許多方便的機能,例如猜文件編碼的函數
guess_encoding(
文件名稱), 非常實用!!!
2015/10/29
igrpah 的學習資源整理
igrpah 是一個在 R 與 Python 的套件,能處理 Social network Analysis
Social network Analysis 能應用的方向還蠻多的,不過如果直接看 Rblogger 上面的文章,我總是覺得有點複雜… 雖然實務上取得資料的確就是要下那麼多苦工…
再參考這篇他教學官網上的這篇(日文,但看程式碼就知道邏輯) https://sites.google.com/site/kztakemoto/r-seminar-on-igraph---supplementary-information
http://codeiq.hatenablog.com/entry/2013/06/25/182324
http://b.hatena.ne.jp/Keiku/igraph/
備註: 日本人使用 Cytoscape 來繪製網路圖形的比例還蠻高的…
Social network Analysis 能應用的方向還蠻多的,不過如果直接看 Rblogger 上面的文章,我總是覺得有點複雜… 雖然實務上取得資料的確就是要下那麼多苦工…
日本生科學者介紹 igraph 基本功能
先看這一篇日本生科學者,簡單的介紹了fb網路如何被匯進R → 製圖 → 分群 → 計算相關指標 http://rpubs.com/kaz_yos/igraph1再參考這篇他教學官網上的這篇(日文,但看程式碼就知道邏輯) https://sites.google.com/site/kztakemoto/r-seminar-on-igraph---supplementary-information
網路群組分組
http://qiita.com/hmj-kd/items/3f2b45b32bc3a8204141http://codeiq.hatenablog.com/entry/2013/06/25/182324
日文書籤網站 igraph
http://doubt-ooo.appspot.com/feed?q=igraphhttp://b.hatena.ne.jp/Keiku/igraph/
TokyoR 聚會的簡報
http://www.slideshare.net/kztakemoto/r-seminar-on-igraphstanford 提供很多 social network analysis 的範例檔
http://snap.stanford.edu/data/egonets-Facebook.html備註: 日本人使用 Cytoscape 來繪製網路圖形的比例還蠻高的…
2015/10/27
用 Docker 協助學習Social Network Analysis
用 Docker 協助學習Social Network Analysis
這次遇到的狀況是用了最新的 R jupyter / Rstudio(R/win) 無法安裝igrpah 套件(??!!),所以只能先找目前網路上已經包裝好的 RStudio Server + igraph下載Docker images(docker pull)
先在google透過關鍵字尋找有沒有被人家包裝好的docker iamges,發現有一個: 我的狀況是透過 VirtualBox 中的 Ubuntu 14執行以下指令 sudo docker pull zachcp/phylogeo執行d ocker images
簡單執行 sudo docker run -d -p 8787:8787 zachcp/phylogeo 預設的帳密 username: rstudio password: rstudio調整桌機 Virtual Box 網路設定
因為我們想要Browser來操作 Rstudio Server版本,又因為VM是在Virtual Box中執行,所以我們要設定轉port;在很多的情境下,都會建議主機ip設定為 127.0.0.1;但此處我直接把ip留空白,因為後續我會在區網利用另一台Mac筆電進行連線,如果此處你設定了 127.0.0.1 則只有本機有機會連線
利用Mac連線PC桌機的Rstudio Server
在筆電的 Chrome 輸入 http://192 .168.1.117:8787下載 Github 上的資料
利用 Rstudio 的 Shell, 輸入: git clone https://github.com/johnmyleswhite/ML_for_Hackers 就可以把資料下載回Rstuio ServerRstudio Server 上下傳資料
下載資料: 在 Files 視窗介面下 -- More -- export 即可把Server上的資料下載回筆電上傳資料: 在 Files 視窗介面下已預設有 Upload 按鈕
保存 Docker images
有時候因為學習需要又下載了新的套件,不想要下次docker run時還要重新安裝一次則可以進行保存sudo docker commit d9ae87d0828a zachcp/phylogeo:v2
其中 d9ae87d0828a 是可以透過 docker ps 查詢到的容器id
不過若是在隨身碟上執行此一指令需時較久,建議還是將過程中的檔案直接下載到本機備份較快
2015/10/14
Windows 處理UTF8 CSV就是悲劇… Excel與R搭配時的解法…
Excel處理CSV UTF8 編碼就是悲劇!!!!
- excel 2016在英文版介面下,匯入文字檔(csv、txt)無法選擇UTF8編碼,只有2種編碼ansi、mac可選
- excel 2016在中文版介面下,匯入文字檔(csv、txt),可選擇UTF8編碼及其他世界各國文字編碼
- 總之微軟放棄不是很想認真處理 UTF8 CSV的問題…
利用Excel協助Data Clean :
- 不要讓excel直接處理csv UTF8格式
- 正常讀取utf的文字編輯軟體打開uft8文件
- 於文字編輯軟體中全選文字→複製貼上至excel→excel中進行資料剖析(這樣比由匯入文字檔還快…)
- Data Clean成功後,直接轉存成xlsx
被excel存檔過後的csv會自動變成BIG5編碼 → 避免夜長夢多,請不要這樣做
excel要存檔成UTF8,有UTF8文字檔的 → 超難用!!!!
PowerBI 也無法處理 UTF8 csv → 存成預設為UTF8的 xlsx 保證沒問題
與R搭配時,不想管編碼問題直接用excel存成xlsx、xls:
- 避免處理編碼的問題時,直接把csv改存成xlsx或xls格式
- 安裝套件 install.packages(
readxl
) # 此套件可讀入單頁sheet- xlsx格式: 使用xml進行資料儲存,預設已是UTF8編碼;可將副標名改為zip後,解壓縮即可驗證
- xls格式: 編碼套件 readxl 會幫忙轉成uft8
- 所以 read_excel 指令中沒有指定編碼的選項!!!
- 讀入資料,記住如果xlsx、xls內有多張sheet要指定sheet,否則只能讀入一個sheet
- 例: read_excel(
/Users/xxx/Downloads/WeareJordan.xls
,sheet=3) - 別忘了在 windows 底下目錄名稱要用2個\指定
- 例: read_excel(
c:\Users\zzz\Desktop\CHINA.xls
)
- 例: read_excel(
- 例: read_excel(
- 在mac底下,讀入的檔名不可以是數字開頭的檔名,例如: 444_js.xls 要改成變數命名規則 js.xls ;winodws則無此限制,但為了未來跨平台,請直接以英文做為檔名開頭
- 在windows底下,檢視匯入的資料時,若非big5編碼內的文字會以uft8的編碼型式顯示;而在mac則無此問題
長治久安之道,資料量小時請存成xlsx,資料量多時請用資料庫管理…
- 資料量少的時候而且資料有大量與Excel協作機會時,可以考慮直接將資料亦寫成 xlsx 輸出
- 安裝套件 install.packages(
openxlsx
) - 使用資料 write.xlsx() 寫檔至 xlsx
- 安裝套件 install.packages(
- 隨著資料愈來愈多,可以考慮存成直接支援uft8的資料庫系統;例如:sqlite可跨平台使用,且支援UTF8openxlsx
- Excel亦支援各式資料庫直接進行連結
windows10 kitematic(docker gui)掛載windows目錄
windows10 kitematic(docker gui)掛載windows目錄
kitematic 提供了GUI介面,以利 docker 的安裝與操作;在官網下載安裝後,一直按下下一步就可以安裝完成;實際上是透過virtual box的方式來達成docker環境的架設。
步驟
- 在docker hub蒐尋 jupyter/datascience-notebook 進行安裝,裝好後即running
- 在 kitematic 介面中尋找 Volumes 進行設定,可以發現無法進行設定
- 執行 Docker Quickstart Terminal
- 輸入 docker ps ,確認一下目前執行的
jupyter/datascience-notebook ID
- 先將jupyter/datascience-notebook給停掉:docker stop
輸入id
- 手動執行以下指令,重點在於 -v 指令,本機直接用 /host 代稱
- docker run -d -p 8888:8888 -e GRANT_SUDO=yes -v /host:/home/jovyan/work jupyter/datascience-notebook
- 原本 ubutnu 底下可以直接指定目錄,但是windows目錄是無法直接掛載
- 回到kitematic 介面中,可以發現會自動命名一個新的容器名稱,且此時可以用GUI方式指定windows目錄…
備註
- 目前kitematic在windows底下的使用,其實不會比直接在vm ubuntu直覺太多,進階指令還是要回到 Docker Quickstart Terminal執行
- kitematic 介面中預設搭配的shell是 powershell,嗯… 非常難用
- 沒有在mac上測試過,我猜mac應該不用這麼麻煩…
2015/10/8
Python 環境切換與管理[簡易版]
Python 環境切換與管理[簡易版]
Python 目前比較麻煩的是有 Python 2 / Python 3 的版本,然後 Mac 也有自帶的Python, 初學者往往在一開始時容易困擾…例如:pip install 套件後,到底是安裝到那一個 python 環境呢? pip3 ?? pip ??
解決方式:
- (1)使用 Pyenv 完全隔開不同的 Python
- 例如:隔開之後再安裝不同版本的 Anacnoda(預設安裝很多的python套件)
- 因為是完全分開的,所以依據你所使用的環境進行 pip install 套件安裝,不會與原先系統預設的python環境對衝
- Anacnoda 官網介紹說 Anacnoda 已經具備有套件與環境管理機能,但依照我自己的使用經驗,建議還是先裝 pyenv 來把環境完全切割比較好…
- (2)使用 Docker image
- 例如:我目前使用這組 Docker image; https://hub.docker.com/r/jupyter/datascience-notebook/
- 好處是已經有了 python 2、python 3、R 的Jupyter
- Python 套件安裝
- 此 Docker 預設的Python環境是 Python3 ,所以如果是 pip install 套件,則會安裝套件至 Python3
- 若要安裝 Python2套件呢?
- 首先要知道 docker 中有多少python環境
- conda env list → 可得知安裝 python2 的環境叫 python2
- 選擇 python2 環境: source activate python2
- 再次使用 conda env list 確認目前的環境
- 使用 pip install 套件。例如: pip install beautifulsoup4
- 安裝後新的套件後(安裝至 python2中),記得下 docker commit 指令把容器的狀態給存起來
- 備註
- 因為 docker 本來就是虛擬化工具,docker中發生了什麼事情對於主系統都不會有什麼影響,所以docker中就沒有必要再安裝 pyenv;當然這是用空間(SSD/HD)來換取煩雜的設定時間損失。
備註:
conda常用指令:- (1)目前作用中的環境安裝了多少python套件 conda list ;
beautifulsoup4 4.4.1
- (2)切換環境
- (3)目前有那些python環境
參考資料: http://conda.pydata.org/docs/_downloads/conda-pip-virtualenv-translator.html
2015/10/7
RCurl 設定 SSL 驗證 [R]
例如:
library(RCurl)
getURL("https://www.python.org" )
會得到
* Error in function (type, msg, asError = TRUE) : error setting certificate verify locations:
CAfile: /etc/pki/tls/certs/ca-bundle.crt
CApath: none
調整為:
library(RCurl)
getURL("https://www.python.org" , ssl.verifypeer = FALSE)
則可取回 Html 文件
2015/10/3
Power BI 利用 ODBC 連接 sqlite
Power BI 利用 ODBC 連接 sqlite
- Power BI 是微軟力推的商業智慧軟體,目前強調在與 excel 高度的整合性;所以被微軟內部視為重要的戰略武器,幾乎每個月都有更新功能… 目前使用限定在 windows 平台,但可以用私人網域郵件申請帳號,就可以將 Power BI的內容以 HTML5 網頁方式呈現
- 但是…
- 其實實務上在資料蒐集的階段,目前 windows 平台不是一個好選擇… 往往我們是在 linux 的 docker 環境中將資料以最簡單的 sqlite 方式予以儲存
- 所以將sqlite的檔案移轉至 windows 平台後利用 ODBC 方式取存是最簡單的
step:
- 安裝 SQLite ODBC
- 在 Power BI 的資料來源中,選取
其他來源
→ODBC
使用以下連線字串 以例中,sqlite文件為 ff123.sqlite 位於 c:\Users\xxx\Downloads\ 資料夾
- DRIVER=SQLite3 ODBC Driver;Database=c:\Users\xxx\Downloads\ff123.sqlite;LongNames=0;Timeout=1000;NoTXN=0; SyncPragma=NORMAL;StepAPI=0;
- 參考網站 :https://www.connectionstrings.com/sqlite3-odbc-driverhttp://www.ch-werner.de/sqliteodbc//
- 成功之後,Power BI還會很無聊的問你帳號與密碼是什麼?
- 隨便填一填就連線成功!
- 支援utf8中文!
備註 :
- 如果你有用過 Excel 舊版中連接資料庫中取得 ODBC 或是 SQL SERVER 就會被目前 Power BI 純工程師介面給嚇到… 突然要你輸入一長串的連線字串,完全沒有提示… 還好 google 找得到
- 如果不用 ODBC, 使用將 sqlite 匯出成 csv 後 → 匯入 Power BI,會有utf8處理中文的問題…
- 目前 Power BI 似乎暫無解決 utf8 csv 的手段
- Excel也有一樣的問題,但可用匯入文字檔的方式才能解決
- sqlite → 轉存 csv → 轉存成 excel 就能解決,但有點複雜
總之利用 ODBC 方式算是 windows 底下處理 sqlite 最簡單的方式!
利用 docker 協助程式學習
作業模式/情境
- 出門帶著 Mac + Docker化隨身碟,確保作業環境為純 linux 開發環境
- 在家使用 PC桌機(16GB) + Docker化隨身碟,確保作業環境為純 linux 開發環境
- 有些在 mac 上極難安裝的程式在 Ubuntu 上的 Docker 異常簡單
- Mac / Windows 雖然都有 Docker Tools 但很難用,還不如直接用虛擬機 Ubuntu設定
- 目前學習 Docker 是為了學習程式開發,暫不學習更進階的議題
- 使用網路爬蟲捉資料時用 PC 桌機上的 linux 的Docker R來進行資料的取得
- 節省 docker 若安裝 mac上 的 SSD空間浪費
- Docker Hub上有各式神人提供的設定好的Dockerfile
step:
- 購置一個市面上販售最快的 64GB 隨身碟(不用1000元)
- 將其格式化為 exFAT
- Mac / Windows / Linux 都可以讀寫
- 在 Mac / Windows 都安裝上 virtual box
- 將 Mac / Windows virtual box 預設的資料夾指向隨身碟
- 下載各式的 Linux Based VM並安裝
- Ubuntu 15 Server
- Ubuntu 14 Server
- Ubuntu 14 Desktop
- Ubuntu + GIS
- 帳號與密碼儘量單一化,因為都是為了學習而非實際生產環境
- 以隨身碟中VM: Ubuntu Server 15為主,進行各項設定
- 安裝 vsftp 以利資料交換
- 安裝 docker
- 安裝 docker 化軟體
- 例如:Jupyter Notebook,以利學習 R / Python / Spark
- 依情境將 virtual box 中的網路設定 port forward
Ubuntu 15 設定 vsftp
主要參考這篇
http://www.liquidweb.com/kb/how-to-install-and-configure-vsftpd-on-ubuntu-15-04/
安裝 vsftp
安裝 vsftp
- apt-get update
- apt-get -y install vsftpd
- anonymous_enable=NO
- local_enable=YES
- write_enable=YES
- chrootlocaluser=YES
- 設定檔中的localumask=002 直接改成localumask=775 才能上檔目錄、檔案
- 使用 filezilla 連線時,記得要選 sftp 協定
- ubuntu 15預設重啟 vsftp 指定修改為: service vsftpd restart,有些教學網頁上的資料是舊的,不適用於 ubuntu15
- 在VM ubuntu 中使用 docker run -v 時設定好共享資料夾,將資料用 ftp 方式回傳至本機
- 因為只有本機有存取的需求,所以不需要設定太繁雜的安全性設定,所以上述直接將 local_umask=775
2015/9/30
部落格寫作流程
部落格寫作流程
寫作原因:
- facebook 的蒐尋機制十分落後,很難期待
- 為自己留下學習與思考上的紀錄
流程:
- 使用 macdown 軟體,以markdown語法編寫,再用html語法貼至 blogger平台
- 以h3做為文章內的次標題(###)
- 貼圖使用 flickr 以利同時發佈到不同的blog平台
- 上傳至flickr私人目錄
- flickr的私人權限是以照片為單位,不是以目錄為單位,為了以利後續批次作業,上傳的圖片的檔名均以
blog
+日期
命名 - flickr 支援外連:點選 flickr share圖示即可取得連結
- 減少圖片的使用,部落格儘量以文字與流程為主,技術細節就直接放在 github
- 程式碼貼至 github gist 以利同時發佈到不同的blog平台
重點:
- 重視問題的流程
- 儘量長話短話講重點
- 儘量維持一定的發文頻率
技術合作:
會在 http://data-sci.info/ 出沒,所以如果有看到文章或是回應與本部落格高度相似的,不用懷疑作者就是我啦… 沒有抄襲的問題在Windows 系統捉取網頁中文資料時會有亂碼,要如何處理?[R]
Q:在Windows 系統捉取網頁中文資料時會有亂碼,要如何處理?
A:使用 library(tmcn) 套件轉utf8
效果節錄:
未使用tmcn套件前:
[1] “\xe7摰單\x87\xae葉敹圾\xe9\xe6\x89偷\xe5 \xe5\xe9\xe5\xe5璈\xe6頧\x9f”
[2] “鈭箸腦\xe6\x96嚗\xb6晷\xe3\u0080擛亦\xb5\u0080\x8d 瞈\u0080瘣芷\xe7\x87\xe6”
使用tmcn套件與 toUTF8 函數後:
[1] “大樹阻台北淡水路 北投警冒雨排除”
[2] “曾抗議連戰赴中被美禁入境 王世堅坦然面對”
2015/9/20
[備忘]使用 Docker 中的R Jupyter,中文顯示與輸出異常??
[備忘]使用 Docker 中的R Jupyter,中文顯示與輸出異常??
問題:
使用 Docker 中的R Jupyter,中文顯示與輸出異常??
輸入中文字串正常,檢查編碼也是 UTF-8
解法:[暫解]
- 在R中設定語系: Sys.setlocale(category = "LC_ALL", locale = "C.UTF-8")
- Sys.setlocale()的效果是暫時性的,下次再開一個新的notebook時需要重新啟用
- 經過測試,在讀入網頁時都會自動轉成 UTF-8 也都能無誤的輸出 UTF-8 資料
- 讀入資料時,例如讀入 BIG5 編碼的 CSV 文件時,只要指定正確編碼格式也能正確讀入R中 ---ex: read.table("ubike-sampledatabig5.csv" ,header=TRUE, fileEncoding="BIG5")
- 網路上有建議將 BIG5 文件全部轉成 UTF-8後再處理,在Linux應該只需要在讀入時指定好編碼格式即可… 因為我測試用 readLines 轉編碼會異常…
- Docker 只是測試環境,所以不想在設定上尋求完美的解法;後續在生產環境時,會是單純的 R 搭配著 zh_TW.UTF-8 的設定
- 聽說在 Linux 版本的 R 不需要擔心編碼問題 ?
- 變數儲存中文無異常;下例: 網路上的即時新聞標題 title_css,直接以 title_css 執行,則正常顯示中文

但是若用 print(title_css)或是 write.table()輸出文字檔,則會出現如下錯誤

經 Encoding(title_css)檢查也是 UTF-8

因為是 Docker 所啟用的ubuntu所以確認語系等相關設定為何?

發現和一般安裝 Ubuntu 的狀況不同…

發現 Docker 中所預設的語系比一般情況下的 Ubntu 少了很多,所以若是在 R 中執行網路上建議的 Sys.setlocale(category = "LC_ALL", locale = "en_US.UTF-8")會有錯誤訊息…

取而代之,我們可以使用

則將變數搭配 print() 或是相關輸出函式時就能正常顯示中文 write.table()
參考文件:
[備忘]使用 Mac Homebrew安裝最新版Sqlite後,系統預設仍是舊版Sqlite3
問題:
使用Homebrew安裝最新版Sqlite後,系統預設仍是舊版Sqlite3???
解法:
(1)因為我有安裝zsh ,所以 ~/.zshrc 的優先權大於~/.bash_profile
因為忘了這個前提,所以花了很多時間在找解法 = ="
(2)確認目前環境中,sqlite3的位置( which sqlite3)
- source ~/.zshrc 再執行which sqlite3 :
- /Users/帳號/anaconda/bin/sqlite3 (版號:3.8.4.1 2014-03-11) 舊版本
- source ~/.bash_profile 再執行which sqlite3:
- /usr/local/bin/sqlite3 (版本:3.8.11.1 2015-07-29) 新版本
由上一步,可以發現不同環境下 sqlite3 位置不同,自然版本也就不同,也難怪依照網路上的建議對 ~/.bash_profile 進行編輯對我無效,將 ~/.zshrc 設定檔中的環境變數調整如下,記得要把/usr/local/bin目錄 置於/Users/帳號/anaconda/bin前面:
export PATH=
/usr/local/bin:/Users/帳號/anaconda/bin
(4)存檔後,重新 source ~/.zshrc 就生效了!
心得:
環境建置有時候真的是一件累人的事情… 也難怪近來 Docker 會如此火紅了
2015/9/19
[備忘] 在Blogger中插入程式碼
現在都儘量使用 markdown 語法來編寫文件,因為很容易轉換成 html 格式文件;然而在google提部的部落格平台中(blogger.com),卻無法簡單的插入程式碼…
舉例來說,在 markdown 軟體中的效果如下:

但是實際顯示變成:

看起來專業程度就差了一半…
網路有很多討論的文章都建議去修改 css 語法,但選擇 blogger.com 做為平台就是希望儘量減少這種麻煩事,專注在文章寫作上;
所以找到了 Github Gist 的解決方法,只要在 Github Gist 建立程式碼後,再到 Blogger 的編寫平台插入 Javascript 即可
例如:
<script src="https://gist.github.com/lovelybigdata/20f71f0089eada9353c0.js"></script>

這樣看來是不是專業多了呢??
另外不知保故,依國外網友們的實測再經過我的測試 Google Blogger 若使用最新的動態檢視版面則一樣無法正常顯示 Github Gist 的程式碼…
舉例來說,在 markdown 軟體中的效果如下:
但是實際顯示變成:
看起來專業程度就差了一半…
網路有很多討論的文章都建議去修改 css 語法,但選擇 blogger.com 做為平台就是希望儘量減少這種麻煩事,專注在文章寫作上;
所以找到了 Github Gist 的解決方法,只要在 Github Gist 建立程式碼後,再到 Blogger 的編寫平台插入 Javascript 即可
例如:
<script src="https://gist.github.com/lovelybigdata/20f71f0089eada9353c0.js"></script>
另外不知保故,依國外網友們的實測再經過我的測試 Google Blogger 若使用最新的動態檢視版面則一樣無法正常顯示 Github Gist 的程式碼…
2015/9/17
簡單好用的 web scraping R 套件 - rvest
近年來很流行網路爬蟲技術,可以自行捉取自己想要的資訊;
只要不是太複雜的網站,使用 R 底下的套件 httr 就可以捉取了;不過由於 httr 並沒有直接支援 CSS 與 xpath 選取,所以還要額外安裝其他的套件來輔助解析網頁資訊。
最近發現到 rvest 這個套件,直接支援 ccs 與 xptah 選取,安裝 rvest 後,在啟用 rvest 時也會順道加入支援 pipeline 編寫,可以有效避免恐怖的巢狀地獄…
rvest 使用如同一般網路爬蟲技術,流程如下所示:
首先我們可以使用 chrome 中的開發者工具 或是 Firefox 中的 Firebug 來協助我們進行選取,可以發現用以下的語法就能正確捉取我們所要的資料…
此處以 css選取(html_nodes函數)舉例,並將資料存成 dataframe 格式,以利串接至資料庫中:
(1)網路爬蟲的入門也蠻簡單的啊~~
(2)即時新聞大部份都不是很重要~~
備註1:使用 xpath 選取
備註2: 想要取捉每篇即時新聞的網址,以利後續捉取內文的話呢??
備註3: 套件作者 Github https://github.com/hadley/rvest
最近發現到 rvest 這個套件,直接支援 ccs 與 xptah 選取,安裝 rvest 後,在啟用 rvest 時也會順道加入支援 pipeline 編寫,可以有效避免恐怖的巢狀地獄…
rvest 使用如同一般網路爬蟲技術,流程如下所示:
- 要捉的網頁真實的網址是什麼 --url =
???
- 把網頁捉下來 --html( )
- 解析(parse)網頁,選取所需內容(使用 CSS 或 XPATH ) --html_nodes()
- 過濾掉其他雜質 -- 此例中我們只留下純文字就好 不留下超連結 html_text()
首先我們可以使用 chrome 中的開發者工具 或是 Firefox 中的 Firebug 來協助我們進行選取,可以發現用以下的語法就能正確捉取我們所要的資料…
- css 選取語法 .picword
- xpath 選取語法 //*[@id='newslistul']/li/a
此處以 css選取(html_nodes函數)舉例,並將資料存成 dataframe 格式,以利串接至資料庫中:
library(rvest)
news_url="http://news.ltn.com.tw/list/BreakingNews"
title_css = html(news_url) %>% html_nodes(".picword") %>% html_text()
my_news = data.frame(title = title_css)
View(my_news)
(1)網路爬蟲的入門也蠻簡單的啊~~
(2)即時新聞大部份都不是很重要~~
備註1:使用 xpath 選取
將html_nodes(".picword")以html_nodes( xpath = "//*[@id='newslistul']/li/a")取代即可備註2: 想要取捉每篇即時新聞的網址,以利後續捉取內文的話呢??
my_news =
data.frame(
title = html(news_url) %>% html_nodes(".picword") %>% html_text() ,
title_href = html(news_url) %>% html_nodes(".picword") %>% html_attr( "href") ,
stringsAsFactors=FALSE) 備註3: 套件作者 Github https://github.com/hadley/rvest
訂閱:
文章 (Atom)