眾所皆知,w indows系統在處理編碼上是非常弱勢的;
相對於 linux 與 mac 在讀寫各式不同編碼的純文件時,只需要指定好 encoding 的內容就可以正常讀取;目前經過我交叉測試,在windows中如果UTF8文件中包含了日文、韓文的UTF8文件還是無法正確讀取…
將問題與解法整理成如下2張圖:
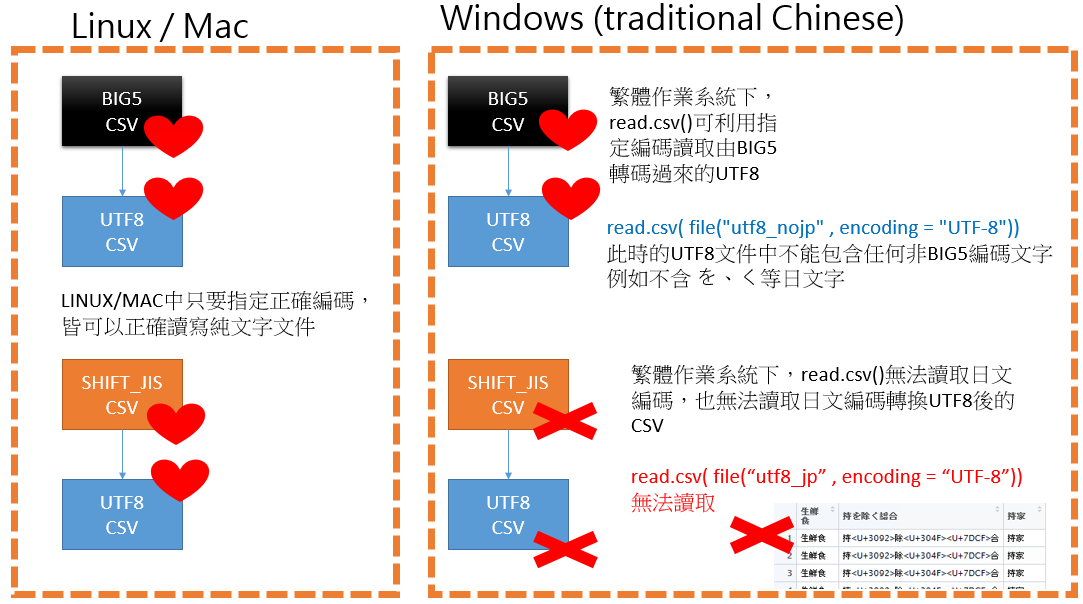

可依情境加以使用不同解決方案,這2種方式都可以正確讀取含有日文、韓文等文字的UTF8文件…若使用原始系統搭載的 read.csv() 則執行指令時會報錯!!
備註:
(1)readxl套件,請參考:
http://www.r-bloggers.com/get-data-out-of-excel-and-into-r-with-readxl/
(2)readr套件,請參考:
http://www.r-bloggers.com/readr-0-2-0/
readr還含許多方便的機能,例如猜文件編碼的函數
guess_encoding(
文件名稱), 非常實用!!!
沒有留言:
張貼留言